Zwei Übungen mit der Schlange - Übung 1, NLP-Tutorial
An was fim nicht alles denken muss!
Umgebungen, Umgebungen, herjemine!
Um den ganzen Kroam zu insdallieren.
Um eine Umgebung für die NLP-Spielereien anzulegen.
Um diese Umgebung dann zu aktivieren.
Schade, dass es sinnvoll ist, es so machen zu müssen. ;-)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[ Ein völlig konfus wirkender Beitrag. Sorry, aber diesmal geht's nicht besser! ]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Nach etlichen Stunden ist es mir nun endlich gelungen, spaCy installiert zu bekommen und dieses sehr informative Tutorial erfolgreich durchzuarbeiten:
https://blog.codecentric.de/2019/03/natural-language-processing-basics/


Damit bin ich endlich auch mal in Sachen Textklassifizierung einen großen Schritt weitergekommen. Uff!
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
list(map(bigrams,speeches))
Natural Language Processing — Einsteigen und loslegen! - codecentric AG Blog
Ich bin sehr glücklich über jedes deutschsprachige Tutorial, was Einsteigern wie mir weiterhilft. Englischsprachige gibt es zuhauf, wie ich mittlerweile weiß. Aber iin der Muttersprache zu lesen und zu lernen ist halt doch einen Tick angenehmer.
Umgebungen, Umgebungen, herjemine!
sudo apt install python3-venv
Um den ganzen Kroam zu insdallieren.
python3 -m venv /home/zarko/nlp_env
Um eine Umgebung für die NLP-Spielereien anzulegen.
source nlp_env/bin/activate
Um diese Umgebung dann zu aktivieren.
Schade, dass es sinnvoll ist, es so machen zu müssen. ;-)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[ Ein völlig konfus wirkender Beitrag. Sorry, aber diesmal geht's nicht besser! ]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Nach etlichen Stunden ist es mir nun endlich gelungen, spaCy installiert zu bekommen und dieses sehr informative Tutorial erfolgreich durchzuarbeiten:
https://blog.codecentric.de/2019/03/natural-language-processing-basics/
Code (etwas chaotisch zusammengewürfelt)
#!/usr/bin/env python
# coding: utf-8
# In[10]:
import spacy
# In[11]:
from spacy.lang.de.examples import sentences
# In[12]:
nlp = spacy.load("de_core_news_sm")
# In[5]:
doc = nlp(sentences[0])
print(doc.text)
for token in doc:
print(token.text, token.pos_, token.dep_)
# In[6]:
# Nachdem der spaCy-Import endlich geklappt hat:
# Weiter im Tutorial:
# Punkt 3
# https://blog.codecentric.de/2019/03/natural-language-processing-basics/
# In[13]:
import pandas as pd
document = nlp("Peter fährt auf seinem Fahrrad und lacht.")
pd.DataFrame({"Token": [word.text for word in document],
"Grundform": [word.lemma_ for word in document],
"Wortart": [word.pos_ for word in document]})
# In[9]:
# Import der Politikerreden
# In[ ]:
# Punkt 1 ff.
# In[12]:
pip install --user xmltodict
# In[19]:
import os
import numpy as np
import pandas as pd
import urllib
import zipfile
import xmltodict
xml_path = 'C:/Users/Thorsten/Documents/NLP-Tutorial/Politikerreden/Bundesregierung.xml'
with open(xml_path, mode="rb") as file:
xml_document = xmltodict.parse(file)
text_nodes = xml_document['collection']['text']
df = pd.DataFrame({'person' : [t['@person'] for t in text_nodes],
'speech' : [t['rohtext'] for t in text_nodes]})
# In[2]:
df.loc[11]
# In[20]:
import seaborn as sns
import matplotlib.pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
get_ipython().run_line_magic('config', "InlineBackend.figure_format = 'svg' # schönere Grafiken")
sns.set()
df["length"] = df.speech.str.len()
sns.countplot(y="person", data=df).set(title="Anzahl an Reden", xlabel='', ylabel='')
# In[21]:
sns.boxplot(y="person", x="length", data=df).set(title="Länge der Reden in Zeichen", xlabel="", ylabel="")
# In[22]:
df = df.groupby("person") .apply(lambda g: g.sample(0 if len(g) < 50 else 50)) .reset_index(drop=True)
df = df[df['person'] != 'k.A.']
# In[7]:
# Fertig Punkt 1 & 2
# In[8]:
# Weiter mit Punkt 3
# In[24]:
def analyze(speech):
with nlp.disable_pipes("tagger", "parser"):
document = nlp(speech)
token = [w.text for w in document]
lemma = [w.lemma_ for w in document]
return (token, lemma)
df["analysis"] = df.speech.map(analyze)
df["tokens"] = df.analysis.apply(lambda x: x[0])
df["lemmata"] = df.analysis.apply(lambda x: x[1])
# In[15]:
# Punkt 4
# In[25]:
def bow(speeches):
word_sets = [set(speech) for speech in speeches]
vocabulary = list(set.union(*word_sets))
set2bow = lambda s: [1 if w in s else 0 for w in vocabulary]
return (vocabulary, list(map(set2bow, word_sets)))
# In[26]:
speeches = [['am', 'Anfang', 'war', 'das', 'Wort'],
['und', 'das', 'Wort', 'war', 'bei', 'Gott'],
['und', 'Gott', 'war', 'das', 'Wort']
]
vocabulary, speeches_bow = bow(speeches)
pd.DataFrame([vocabulary] + speeches_bow, index=['vocabulary'] + speeches)
# In[27]:
def bigrams(speech):
return list(zip(speech[:-1], speech[1:]))
list(map(bigramify, speeches))
# In[ ]:
import spacy
from spacy import displacy
# In[31]:
nlp = spacy.load('de_core_news_sm')
text = """Donald wusste noch nicht, dass er am Montag in Entenhausen 0.3141 Taler an den Herrn Dagobert zurückzuzahlen hatte."""
doc = nlp(text)
svg = displacy.render(doc, style='ent', jupyter=True)
# In[32]:
# Punkt 5
# In[33]:
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
def train_test_evaluate(speeches, persons):
# Durchnummerieren der Redner
encoder = LabelEncoder()
y = encoder.fit_transform(persons)
# Bag of Words der Reden extrahieren
vectorizer = CountVectorizer(binary=True)
X = vectorizer.fit_transform(speeches).toarray()
# Daten aufteilen für Training und Test
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3)
# Klassifikator trainieren und testen
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Vorhersage-Genauigkeit auswerten
print(accuracy_score(y_test, y_pred))
sns.heatmap(confusion_matrix(y_test, y_pred),
xticklabels=encoder.classes_,
yticklabels=encoder.classes_)
# In[34]:
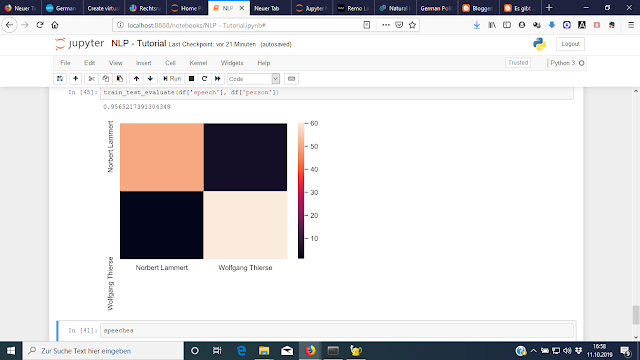
train_test_evaluate(df['speech'], df['person'])
# In[35]:
# Test mit anderen Reden
# In[36]:
xml_path = 'C:/Users/Thorsten/Documents/NLP-Tutorial/Politikerreden/Bundespräsidenten.xml'
with open(xml_path, mode="rb") as file:
xml_document = xmltodict.parse(file)
text_nodes = xml_document['collection']['text']
df = pd.DataFrame({'person' : [t['@person'] for t in text_nodes],
'speech' : [t['rohtext'] for t in text_nodes]})
# In[ ]:
def analyze(speech):
with nlp.disable_pipes("tagger", "parser"):
document = nlp(speech)
token = [w.text for w in document]
lemma = [w.lemma_ for w in document]
return (token, lemma)
df["analysis"] = df.speech.map(analyze)
df["tokens"] = df.analysis.apply(lambda x: x[0])
df["lemmata"] = df.analysis.apply(lambda x: x[1])
# In[ ]:
def train_test_evaluate(speeches, persons):
# Durchnummerieren der Redner
encoder = LabelEncoder()
y = encoder.fit_transform(persons)
# Bag of Words der Reden extrahieren
vectorizer = CountVectorizer(binary=True)
X = vectorizer.fit_transform(speeches).toarray()
# Daten aufteilen für Training und Test
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3)
# Klassifikator trainieren und testen
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# Vorhersage-Genauigkeit auswerten
print(accuracy_score(y_test, y_pred))
sns.heatmap(confusion_matrix(y_test, y_pred),
xticklabels=encoder.classes_,
yticklabels=encoder.classes_)
# In[ ]:
train_test_evaluate(df['speech'], df['person'])
# In[ ]:
speeches
# In[ ]:
Zwei Screenshots der Outputs



Damit bin ich endlich auch mal in Sachen Textklassifizierung einen großen Schritt weitergekommen. Uff!
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Nachtrag:
list(map(bigrams,speeches))
[[('am', 'Anfang'), ('Anfang', 'war'), ('war', 'das'), ('das', 'Wort')],
[('und', 'das'),
('das', 'Wort'),
('Wort', 'war'),
('war', 'bei'),
('bei', 'Gott')],
[('und', 'Gott'), ('Gott', 'war'), ('war', 'das'), ('das', 'Wort')]]
Das "bigrammify" (siehe oben!) habe ich entweder nicht verstanden, oder es war vlt. ein Tippfehler in der ansonsten perfekten Anleitung - die übrigens zu weiteren, sicher sehr interessanten Artikeln verlinkt:
Dies zeigt uns, dass die Fehler bei der Klassifikation hauptsächlich bei Reden von Christina Weiss aufgetreten sind — diese wurden von unserem Klassifikator recht oft Bernd Neumann beziehungsweise Michael Naumann zugeschrieben. Vielleicht kann hier das tf-idf-Maß helfen? Oder neuronale Netze?
Mehr dazu und viele weitere spannende Themen rund um Machine Learning und Deep Learning bietet das codecentric.AI-Bootcamp!
Thomas hat in Mathematik promoviert, Erfahrung in der Forschung und Weiterbildung gesammelt und verstärkt seit Oktober 2018 das Team in Münster im Bereich Data Science/Machine Learning. Besonders interessieren ihn alle Themen rund um KI und Deep Learning.
Natural Language Processing — Einsteigen und loslegen! - codecentric AG Blog
Ich bin sehr glücklich über jedes deutschsprachige Tutorial, was Einsteigern wie mir weiterhilft. Englischsprachige gibt es zuhauf, wie ich mittlerweile weiß. Aber iin der Muttersprache zu lesen und zu lernen ist halt doch einen Tick angenehmer.



Kommentare
Kommentar veröffentlichen